
























Researchers develop cybersecurity test for AI being used by Google
Rochester Institute of Technology experts have created a new tool that tests artificial intelligence (AI) to see how much it really knows about cybersecurity. And the AI will be graded.
The tool, called CTIBench, is a suite of benchmarking tasks and datasets used to assess large language models (LLMs) in Cyber Threat Intelligence (CTI). CTI is a crucial security process that enables security teams to proactively defend against evolving cyber threats.
The evaluation tool comes at a time when AI assistants claim to have security knowledge and companies are developing cybersecurity-specific LLMs. For example, Microsoft Copilot has an integrated security platform.
Until now, there has been no way to tell if an LLM has the capability to work as a security assistant.

Nidhi Rastogi, assistant professor in the Department of Software Engineering
“Is the LLM reliable and trustworthy?” asked Nidhi Rastogi, assistant professor in RIT’s Department of Software Engineering. “Can I ask it a question and expect a good answer? Will it hallucinate?”
CTIBench is the first and most comprehensive benchmark in the Cyber Threat Intelligence space. The tool is already being used by Google, Cisco, and Trend Micro.
“We should embrace using AI, but there should always be a human in the loop,” said Rastogi. “That’s why we are creating benchmarks—to see what these models are good at and what their capabilities are. We’re not blindly following AI but smartly integrating it into our lives”.”
In her AI4Sec Research Lab, Rastogi is studying at the crossroads of cybersecurity and AI. She developed CTIBench along with computing and information sciences Ph.D. students Md Tanvirul Alam, Dipkamal Bhusal, and Le Nguyen.
The RIT team began by working on SECURE, a benchmark focused on evaluating LLMs in the context of industrial control systems. A paper on SECURE was later accepted to the 2024 Annual Computer Security Applications Conference.
“That experience made us realize how critical it is to evaluate LLMs in other high-stakes domains,” said Bhusal. “Since there was no reliable benchmark for CTI, we felt it was the right time to build one.”
CTIBench is like a test on how much a LLM knows. Throughout the five different benchmarks, the AI completes tasks as if it is a security analyst at a security operations center. Tasks include root cause mapping and calculating Common Vulnerability Scoring System scores.
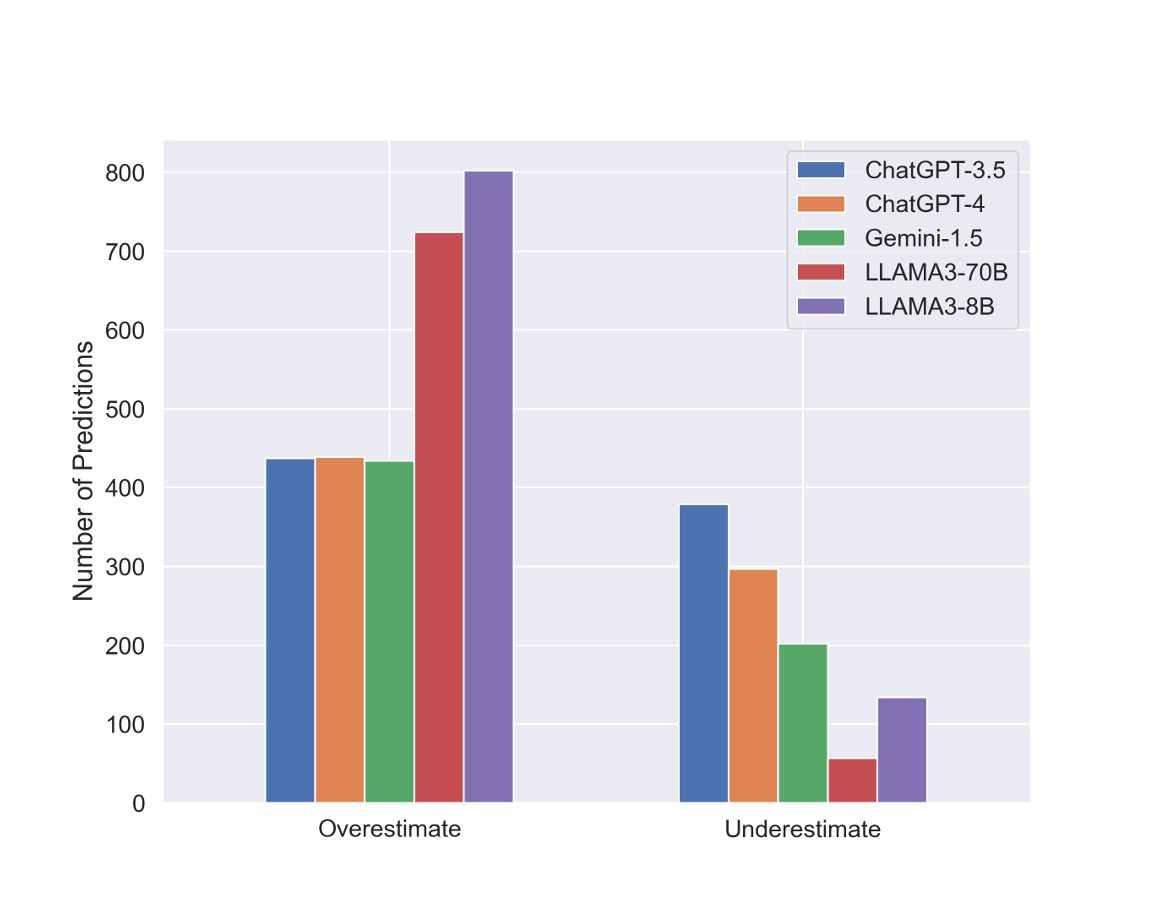
A graph from the paper illustrates the number of overestimations and underestimations made by different LLMs when predicting the severity score of security flaws in information systems. All models exhibit a higher frequency of overestimation compared to underestimation, which suggests that LLMs may need calibration to improve their accuracy in threat severity prediction.
The RIT team also created 2,000 cybersecurity questions using ChatGPT—with a lot of trial and error in prompt engineering the questions. All the questions were validated by real security professionals and cybersecurity graduate students. Questions in the evaluation range from basic security specialist definitions to technical NIST specifications to determining the next steps of a threat situation.
“One of the most challenging and rewarding aspects was designing appropriate tasks to quantitatively evaluate the capabilities of LLMs in the domain of Cyber Threat Intelligence,” said Alam.
While creating CTIBench over several months, the RIT team ran the tool through five different LLMs. In the end, the benchmark provides an evaluation of the LLM it is testing—showing its percentage of accuracy on the different tasks.
The researchers published “CTIBench: A Benchmark for Evaluating LLMs in Cyber Threat Intelligence” at NeurIPS 2024, the Conference on Neural Information Processing Systems. It was a spotlight paper among the top 2 percent accepted at NeurIPS.
Now, industry has taken notice of CTIBench. It is free and open access—available on the Hugging Face API and GitHub.
Google is using CTIBench to evaluate its new experimental cybersecurity model Sec-Gemini v1. Cisco and Trend Micro are using CTIBench to evaluate cybersecurity applications in their own LLMs. Chris Madden, a distinguished technical security engineer at Yahoo Security, has also brought attention to CTIBench in his Common Weakness Enumeration benchmark effort in collaboration with the MITRE Corporation.
“The quick adoption of CTIBench validates our research impact and positions us well in cybersecurity and LLM research,” said Rastogi. “This is opening doors to new collaborations, funding, and real-world industry impact.”
Latest All News
- Heidi Miller retires after nearly 32 years with the physician assistant programRIT’s physician assistant program celebrated its 30th graduating class this year, and now its biggest champion, former director and founder Heidi Miller, is preparing to retire at the end of June after nearly 32 years. Miller developed the PA program and introduced a unique major focused on direct patient care. In the late 1980s, Miller worked at Rochester General Hospital as a physician assistant specializing in emergency medicine. Her reputation for mentoring younger PAs led to an invitation to join an RIT task force considering a new major for the College of Science. In 1993, Miller wrote the PA curriculum, prepared the program for approval, and became the program’s first director. The following year, Nancy Valentage joined the program to help navigate clinical partnerships, and together they graduated the first class in 1995. Recognition of the profession in the late 1980s and early 1990s as an accessible and affordable healthcare option gave the field, established in the mid-1960s, a boost as the next medical profession. “RIT jumped on that,” Miller said. “We were the 54th program in the country, and right now there are over 300. We were right on the cusp of a significant growth and expansion of the profession.” As the medical program gained momentum, prospective students vied for a limited number of seats. (Enrollment is tied to available training opportunities at clinical partnerships.) In 2011, the PA program helped anchor RIT’s new College of Health Sciences and Technology. The college grew from a strategic partnership between RIT and Rochester Regional Health. The RIT-Rochester Regional Health Alliance, which includes Rochester General Hospital, strengthened collaborative opportunities with Miller’s former employer. “It was a full-circle moment for me,” she said. Below, Miller shares reflections from her time at RIT and looks forward to the future. What are you most proud of when looking back at your time at RIT? We have always had a team approach, even from the first years of training students, to recognize that they were entering the field of medicine as part of a team. Everybody has to work closely together for the best care of the patient, which was the core philosophy that we tried to impart onto the students. What are some of your fondest memories? Certainly, graduating the first class, moving the undergraduate program to a five-year BS/MS in 2016, and creating the Annual Awards and White Coat ceremony. I think, for many students, getting their long white professional coat is probably more meaningful than graduation. I also have fond memories of the many dedicated colleagues who have advocated, supported, and helped create and grow this program. We couldn’t have prepared our students without the support of the medical community—RIT-RRH Alliance and the University of Rochester—in training, recruiting, and employing a lot of our alumni. It ‘takes a village’ to train competent, compassionate, and hard-working patient care providers. Many of our alums have stayed in the area and work in the two big health systems, as we know it now, so I think our program has contributed to the workforce. What are your retirement plans? I’m a member of the Rochester Academy of Medicine Board of Trustees, and I hope to increase my volunteer time. I also do a fair amount consulting with New York State Department of Health in professional practice areas. I am an avid reader, and I also hope to do more writing. I’m involved with the PA History Society, based out of Atlanta, and I am currently finishing a historical dissertation on the profession. In a different area, I have a soft spot for animals, and so volunteering at animal sanctuaries is high on my list. My family and I are planning a trip to Italy in August, and we’re looking forward to it. Both of our daughters recently graduated from graduate programs, and so this is kind of a big celebratory trip for all.
- Professor Emeritus Denis Defibaugh named 2025 Guggenheim FellowIn the early 20th century, American painter Rockwell Kent made several trips to Greenland to document what he called an “earthly paradise.” Nearly a century later, Denis Defibaugh felt inspired by Kent and made his own pilgrimage to the island in 2016. Like Kent, Defibaugh fell in love with the culture and landscape of Greenland. His passion and the photos he captured helped earn him a 2025 John Simon Guggenheim Memorial Foundation Fellowship. According to the foundation, this year marks the 100th class of Guggenheim Fellows, which includes 198 individuals working across 53 disciplines. Fellows were chosen from a pool of nearly 3,500 applicants. Defibaugh, professor emeritus in RIT’s School of Photographic Arts and Sciences, explained that he has been interested in Greenland and Kent’s work for as long as he can remember. During a chance meeting with the director of the Rockwell Kent Gallery and Collection, located at the SUNY Plattsburgh State Art Museum, Defibaugh came across a collection of photographs on lantern slides that Kent took during one of his visits to Greenland. Before then, Defibaugh had no idea Kent documented his visits in this way. “When I pulled the first one out, I said ‘wow, this is like a diamond.’ I was so blown away by them,” said Defibaugh. “Kent used the slides when he came back from Greenland to do lecture tours. Almost every lecture sold out, so he lectured until he made enough money to go back to Greenland for another year. It was a constant cycle.” Denis Defibaugh Katrina Zeeb in a traditional Greenlandic outfit worn for special occasions. When Kent lived in Illorsuit, this was the normal attire for women. After this discovery, Defibaugh planned his first trip to Greenland. He received a National Science Foundation grant to support his travel after several application attempts, and the photographs and observations he made during his 16-month stay were documented in his book North By Nuuk: Greenland After Rockwell Kent. The Guggenheim Fellowship will enable Defibaugh to return to Greenland, continue his study of native culture, and build upon his current body of work. Defibaugh said he will return to some of the villages he saw in 2016, including Uummannaq, Nuuk, and Sisimiut, but not Illorsuit. Unfortunately, the waterside village was abandoned in 2017 after a landslide caused a megatsunami on the Karrat Fjord just two months after Defibaugh returned to the United States. “Illorsuit was this little settlement on a beautiful, horseshoe-shaped black sand beach. On one side of the town was the fjord, and on the other was this giant black mountain. When the tsunami hit, the villagers had to evacuate and they were told they couldn’t go back,” said Defibaugh. “I thought a good reason for me to return to Greenland would be to see how people’s lives have changed since then.” Denis Defibaugh Nuka-Sofie Fleishcher Lovstrom reclining in front of her son’s painting. Defibaugh will travel to Greenland for roughly one month, from mid-July to mid-August this year. He said the knowledge and connections he gained during his first trip will give him an advantage when planning what he wants to capture during his upcoming visit. “I want to try to be a little more experimental with this trip,” he said. “I’d like to do something that evolves the whole North by Nuuk project. I just have to figure out what that looks like.” Later this year, photographs from North by Nuuk will be exhibited in the Rose Lehrman Art Gallery at Harrisburg Area Community College. The exhibition will be open to the public Oct. 6 through Nov. 7, and Defibaugh will give a lecture about his work on Oct. 16. More information about Defibaugh’s first visit to Greenland can be found on his portfolio website. Go to the John Simon Guggenheim Memorial Foundation website for more details about the fellowship.
- Interpreter Richard “Smitty” Smith to retire after 46 years at NTIDRichard Smith remembers pivotal moments that led to his career path as an ASL-English interpreter. When he was 16 years old, he had the opportunity to see a sign-language interpreter at work. After that, he signed up for free sign-language classes offered at RIT. “It was these moments, along with others, that made me realize this was the work I wanted to do and that NTID was where I wanted to be,” said Smith. Forty-six years later, “Smitty,” as he affectionately known on campus, will retire June 30 from his role as curriculum support/materials development coordinator in NTID’s Department of American Sign Language-English Interpretation. Throughout his career, Smith, who started at NTID in 1979, has earned several awards, including the Alice Beardsley Professional Interpreter of the Year Award, the Department of Interpreting Services Interpreter Emeritus Award, the Genesee Valley Region Registry of Interpreters Service Award, and the Rochester Deaf Kitchen Most Valuable Interpreter Award. He has also twice received the NTID Advisory Group Award. “NTID has given me far more than I have contributed—a life, a career, and a purpose,” he said. “I was fortunate to be in the right place at the right time and couldn’t be more grateful.” How has the field of ASL interpreting changed throughout the years? The field has changed quite a bit. There is more research and new and different ways of looking at things and more Deaf colleagues interpreting and taking on leadership roles. There is also more open dialogue, which is truly wonderful. When I first started, there were no degree programs offered for interpreters—just training programs. Now, interpreters can earn a doctoral degree or specialty certificates, such as interpreting in healthcare. What will you miss most after you retire? Hands down, I will miss seeing all of the students—Deaf, hard-of-hearing, and hearing—grow and become leaders. I will also miss talking about ASL and the work that we do as interpreters. What are a few of your most memorable interpreting assignments? I had the opportunity to work in China and see the Great Wall. I was also able to interpret in the beautiful city of St. Petersburg in Russia. It was also a pleasure to work as an interpreter on the social work team within Interpreting Services for eight years. Those were the best years. What are your plans during retirement? I have plans to go to the gym, volunteer at the Rochester Deaf Kitchen food pantry, and continue with my hobby of making raised garden beds, rolling plant stands, and holiday ornaments from scrap wood and recycled materials. Oh, and I plan to take naps.
- AI brain-computer interface expert and former Oxford University professor joins RITFormer Oxford University professor Newton Howard is fueled by his fascination with quantum biology and neuroscience. He believes there is a future where we can not only understand the brain at a deeper level but unlock new ways to enhance cognitive function and treat neurological disorders. This fall, Howard will bring his enthusiasm and expertise to Rochester Institute of Technology’s School of Individualized Study as a professor of practice. Howard is the founder of ni2o, Inc., an organization dedicated to enhancing cognitive and athletic performance for those affected by neurological conditions. His career has spanned academia, the U.S. military, and the private sector, and he is known for transforming research into real-world applications, including having roles in developing technologies such as wireless hotspots, Google Earth, and Google Translate. He has several U.S. patents, presented at national and international conference, and has published journal articles, papers, and textbooks. As a former professor at Oxford, where he is still a member of the university’s congregation, MIT, and Georgetown University, Howard founded and directed multiple laboratories, including the Computational Neurosciences Lab at Oxford and the Synthetic Intelligence Lab at MIT. He is also the founder of The Howard Brain Sciences Foundation and C4ADS (Center for Advanced Defense Studies), a think-tank dedicated to data-driven analysis of global conflicts and transnational security threats. “RIT is a university on the cutting-edge of technology, the arts, and design, and Newton Howard is a perfect representation of our mission and aspirational thinking,” said James Hall, dean of RIT University Studies and executive director of the School of Individualized Study. “We are thrilled that Dr. Howard will share his spirit of innovation and entrepreneurship with our students who are always on the lookout for ways to pursue opportunities to make a positive difference in the world.” RIT’s Professor of Practice designation recognizes industry professionals with extensive experience in their fields who bring real-world knowledge and expertise into the classroom. This fall, Howard will be supporting RIT partnerships with alumni in the private and public sectors while continuing to conduct research that advances understanding of the brain and the development of neural prosthetics to treat brain and neurological diseases. As he looks ahead to interacting with students and faculty this fall, Howard says, “As we work together at RIT, we are not just shaping minds, but shaping the future. The greatest discoveries happen when we embrace the diversity of thought, challenge our assumptions, and learn from one another. I look forward to contributing to a community where both faculty and students are partners in the pursuit of knowledge. It is through genuine interaction, shared insight, and interdisciplinary collaboration that we can create meaningful advancements.”
- COSMOS-Web opens window into universe for scientists and citizensCOSMOS-Web was the largest General Observer program selected by the James Webb Space Telescope for Cycle 1. The team, led by RIT Associate Professor Jeyhan Kartaltepe, has publicly released its full data set, including a catalog and an interactive viewer. The release gives the largest look at the deep universe ever, providing data for scientists to make future discoveries. Already, scientists have found a treasure trove of early galaxies. COSMOS-Web provides the largest view deep into the universe ever, and now an easily searchable catalog with all of the data is available to the public. COSMOS-Web was the largest General Observer program selected for Cycle 1 of the James Webb Space Telescope (JWST). The survey mapped 0.54 square degrees of the sky (about the area of three full moons) with the Near Infrared Camera (NIRCam) and a 0.2 square degree area with the Mid Infrared Instrument (MIRI). While previous surveys have aimed to help astronomers map and understand what exists in the vast universe, the advanced instruments of JWST have allowed COSMOS-Web to study galaxy evolution through a long range of history. “The sensitivity of JWST lets us see much fainter and more distant galaxies than ever before, so we’re able to find galaxies in the very early universe and study their properties in detail,” said Jeyhan Kartaltepe, associate professor at Rochester Institute of Technology and lead researcher of COSMOS-Web. “The quality of the data still blows us away. It is so much better than expected.” COSMOS2025, the catalog containing the photometry, morphology, redshifts, and physical parameters of galaxies from COSMOS-Web, delivers a combination of sensitivity, spatial resolution, and field-of-view to observe nearly 800,000 galaxies. Using JWST imaging, ground-based telescope data, and previous COSMOS data, the catalog makes an unprecedented amount of information freely available, opening many unexplored scientific avenues. The full COSMOS-Web color image is shown with a zoom in to the region surrounding a gravitationally lensed galaxy known as the COSMOS-Web ring (Mercier et al. 2024).Credit: Kartaltepe/Casey/Franco/COSMOS-Web “This was an ambitious undertaking that required the development of innovative technologies to simultaneously measure the photometry and morphology of nearly 800,000 galaxies across 37 images,” said Marko Shuntov, postdoctoral researcher at Cosmic DAWN Center. “Building the catalog required tremendous teamwork, and it was all worth it because ultimately it has delivered some of the highest quality redshifts and physical parameters of galaxies that will enable groundbreaking science.” The raw data retrieved during COSMOS-Web was so vast that it was difficult and incredibly time-consuming for scientists to work through it. The public availability of the catalog takes that work out of the equation for the community. The COSMOS-Web team worked to reduce the data, eliminating artifacts, subtracting backgrounds, and improving the astrometry in order to provide accurate photometric and morphological analyses. The breakthroughs already discovered through JWST’s observations have shown how essential NIRCam data is for understanding galaxies in the early universe. Ensuring that the data are science-ready is an achievement that makes COSMOS-Web the standard calibration for future, large surveys. “We combined more than 10,000 images of the sky together to form the largest contiguous image available from JWST,” explained Maximilien Franco, postdoctoral researcher at Université Paris-Saclay. “To do this, we needed to ensure that all the images were properly aligned with existing data, and also to correct for any observational biases. It was incredible to reveal galaxies that were previously invisible, and very gratifying to finally see them appear on our computers.” Likewise, MIRI plays a critical role in determining the mass of early galaxies and investigating star formation over cosmic time. It has already been instrumental in confirming some of the most distant galaxies discovered by JWST. Using longer wavelengths that are less affected by dust extinction, MIRI has the ability to detect and characterize galaxies at higher redshifts, or at earlier times in the universe. “With MIRI, we’re now accessing an unprecedented level of detail in this wavelength range, providing new insights into the processes driving galaxy evolution and the growth of black holes,” said Santosh Harish, postdoctoral research associate at RIT. “The leap in sensitivity and spatial resolution is extraordinary, and MIRI observations from COSMOS-Web are a fine example of what this instrument is capable of.” Along with the data itself and three initial papers on the catalog, near infrared imaging, and mid infrared imaging, the data release also includes an interactive viewer where users can directly search images for specific objects or click on objects to see their properties. In addition, two new COSMOS-Web studies—one examining the structural evolution of brightest group galaxies over the past 11 billion years and another applying artificial intelligence to estimate key galaxy properties from photometry—highlight the wide scientific potential of the catalog. “Thanks to JWST and the COSMOS-Web survey, we can now trace how galaxies shut down star formation, undergo morphological transformation, and how these processes are shaped by their environment across cosmic time, even predicting galaxy properties using AI-driven methods,” said Ghassem Gozaliasl, astrophysicist and researcher at Aalto University. When the JWST launched in 2021, the COSMOS-Web team of nearly 50 researchers around the world had the longest observing time during the telescope’s first year. The team set out with three primary goals: to map and build understanding of the Reionization Era (in the universe’s first billion years); to trace and identify massive galaxy evolution in the first two billion years; and to study how dark matter is linked to visible matter within galaxies. The COSMOS-Web team is made up of nearly 50 researchers from around the world. The group gathered for a conference ahead of their full data release in Marseille, France, in May. Credit: COSMOS-Web After more than 150 visits and 250 hours of observations, the JWST data from COSMOS-Web has provided the information to obtain those goals. The survey has sent scientists into a new age of space observation and data analysis, and has opened the door to a future of understanding and discovery like never before. “We have data and catalogs that we’re very sure of, that we’ve tested and put a lot of work into,” said Kartaltepe. “I can’t overstate how much the field has changed. With data from JWST, we now have a new window on the universe.” COSMOS-Web is jointly led by Kartaltepe and Caitlin Casey, professor of physics at University of California, Santa Barbara, and is part of The Cosmic Evolution Survey (COSMOS). Beginning in 2007, COSMOS joined together more than 200 scientists across the globe to study the formation and evolution of galaxies using both space-based and ground-based telescopes. The remarkable longevity of the collaboration is a testament to the importance of open, accessible science. To learn more For more information on COSMOS-Web, go to the program’s website. The COSMOS-Web images, catalog, and interactive viewer are available through the team’s data release website.
- Summer construction projects underway at RITThe campus may seem quiet, but RIT Facilities Management Services is in high gear, racing to complete construction projects before students return in late August. The team is tasked with completing over 100 projects in a span of just 12 weeks, according to Michael Dellefave, director of Construction/Project Management. “It’s pretty amazing what the project managers and all the contractors are able to complete in a very short summer window,” said Dellefave. Peter Schuck/RIT Construction is continuing at the Music Performance Theater, pictured, and Tiger Stadium. Both facilities should be open to the public in January 2026. Among the major efforts is the renovation of the University Services Center, bringing Student Financial Services, the RIT Service Center, and the ID Card Office under one centralized roof. The redesigned space aims to provide a modern, accessible environment, complete with both front and back of house customer service experiences, a technology support lab, and collaborative work and leisure spaces. Furniture installation is scheduled for completion by mid-July, and all services will be operational for the upcoming fall semester. “The project's objective was to seamlessly integrate multiple essential functions,” said Marielle Santoriello, senior project manager. “The goal was to create an ambiance reminiscent of an Apple Store—clean, modern, inviting. Additionally, we aimed to encourage students, faculty, and staff to relax, eat, and work while they wait for support.” Here are some other projects happening this summer: Residence Halls: This summer marks the third full year of a multi-year plan to modernize RIT's residence halls. Helen Fish Hall and Carlton Gibson Hall are undergoing extensive renovations, including updates to hallways, restrooms, lounges, lighting, carpeting, and ceilings. Notably, air conditioning will also be installed. In addition, more than 400 rooms in Eugene Colby Hall and Gleason Hall are being fitted with new doors and smart lock systems. These upgrades are scheduled for completion by mid-August. Peter Schuck/RIT Carlton Gibson Hall, pictured, and Helen Fish Hall are undergoing extensive renovations this summer, including updates to hallways, restrooms, lounges, lighting, carpeting, and air conditioning. Music Performance Theater: The construction of the new music performance theater remains on schedule, with a scheduled completion date in January 2026. The theater will feature a 750-seat auditorium, two balconies, and a historic 100-year-old restored theater organ, poised to be one of the largest functioning theater organs in the region. Exterior work is expected to be completed by the end of this summer, with interior finishes underway. Tiger Stadium: A state-of-the-art facility designed to support RIT’s lacrosse and soccer programs, is also on track for a January 2026 completion. The stadium will include seating for 1,180 spectators, team locker rooms, a training room, media suite, concession area, and a hospitality room with a glass viewing wall. Tiger Stadium will be the host site for the 2028 NCAA Division III Women’s Lacrosse Championship. D Lot will continue to operate at a limited capacity until the beginning of the spring 2026 semester. Academics and research: Construction has commenced at 175 Jefferson Road, the former Radisson Hotel, to establish a dedicated space for a future Occupational Therapy program. The facility is slated for completion shortly after January 2026. Peter Schuck/RIT Construction has begun at 175 Jefferson Road, home to the future Occupational Therapy program. This project is slated for completion in early 2026 NTID: Classroom renovations are being finalized this summer, including the addition of Zoom rooms equipped with appropriate lighting for interpreters. Plans for a new Student Support Center and a redesigned north entry are in development, with groundbreaking anticipated early 2026. Park Point: Renovations are underway to expand the current RIT Certified space on the second floor. The space is slated to be complete by late fall. Despite the various construction projects, no major roadwork is expected on campus this summer, according to Dellefave.





